░░░░░░░ WEEK 5 ░░░░░░░
Preliminary Survey Measurement
In my preliminary survey, I made adjustments before the experiment and created an explanation chart for my
paper, elucidating how these questions were selected and their relevance to each indicator of algorithm
literacy.
Fortunately, the survey responses exhibited varying levels of algorithm literacy, enabling me to
categorize the subjects into two groups. However, I encountered a challenge: certain algorithm literacy
indicators in the ALEC were associated with multiple responses, necessitating careful consideration. Even
if a subject demonstrated low literacy levels in one question, their response to another related question
could positively impact their scores.
Furthermore, I factored in the subjects' occupation and age to estimate their initial algorithm literacy
levels. For instance, considering that Subject A works as a content quality analyst, it's reasonable to
presume they possess more knowledge about algorithmic processes. There is a significant age gap of 14
years between my oldest and youngest subjects, during which pre-tertiary education syllabi underwent
considerable changes, with a greater emphasis on technology in later years. Subject D (19) likely received
exposure to computing as part of their secondary school education since its integration in 2017.
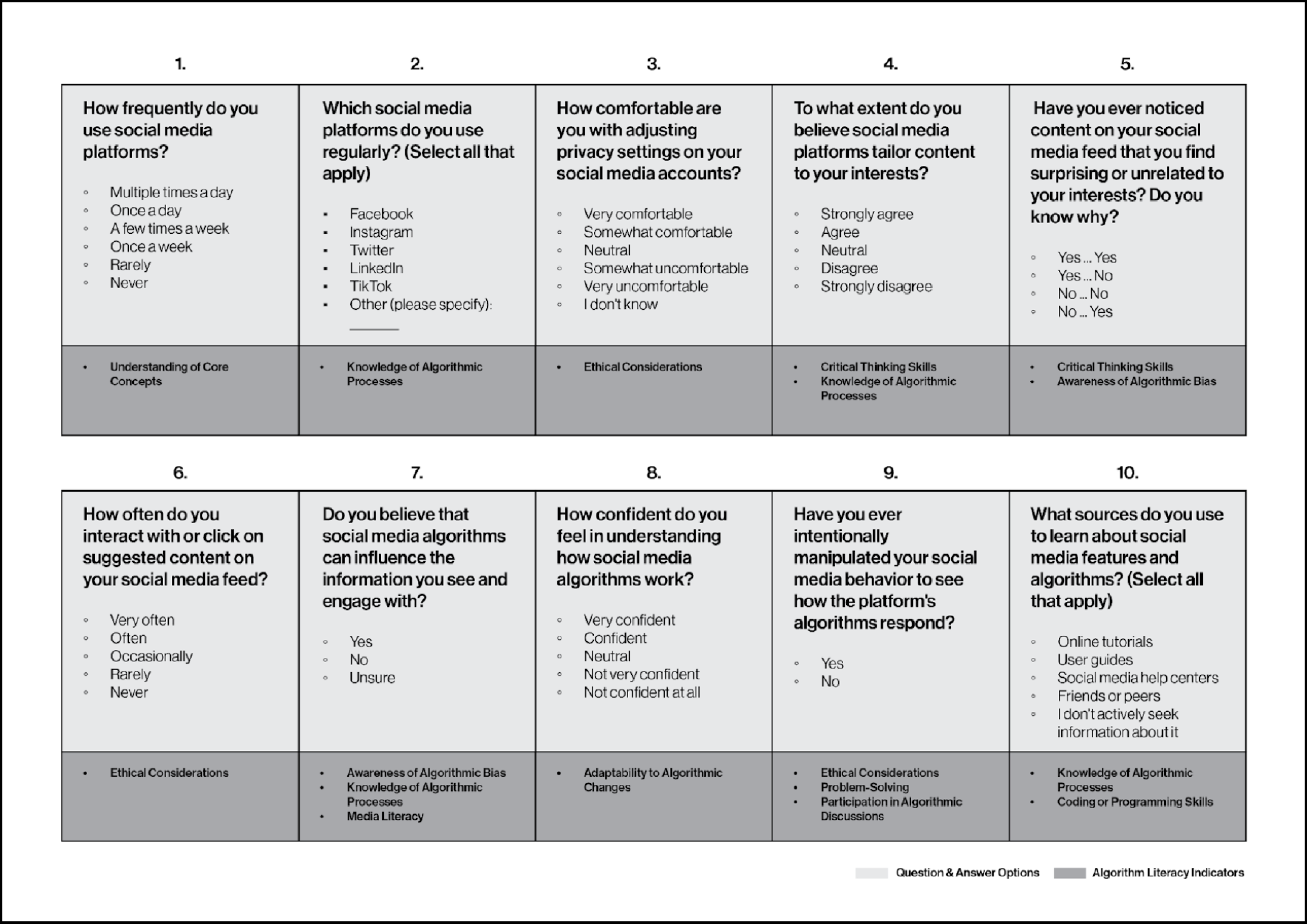
Preliminary Survey Questions & Indicators
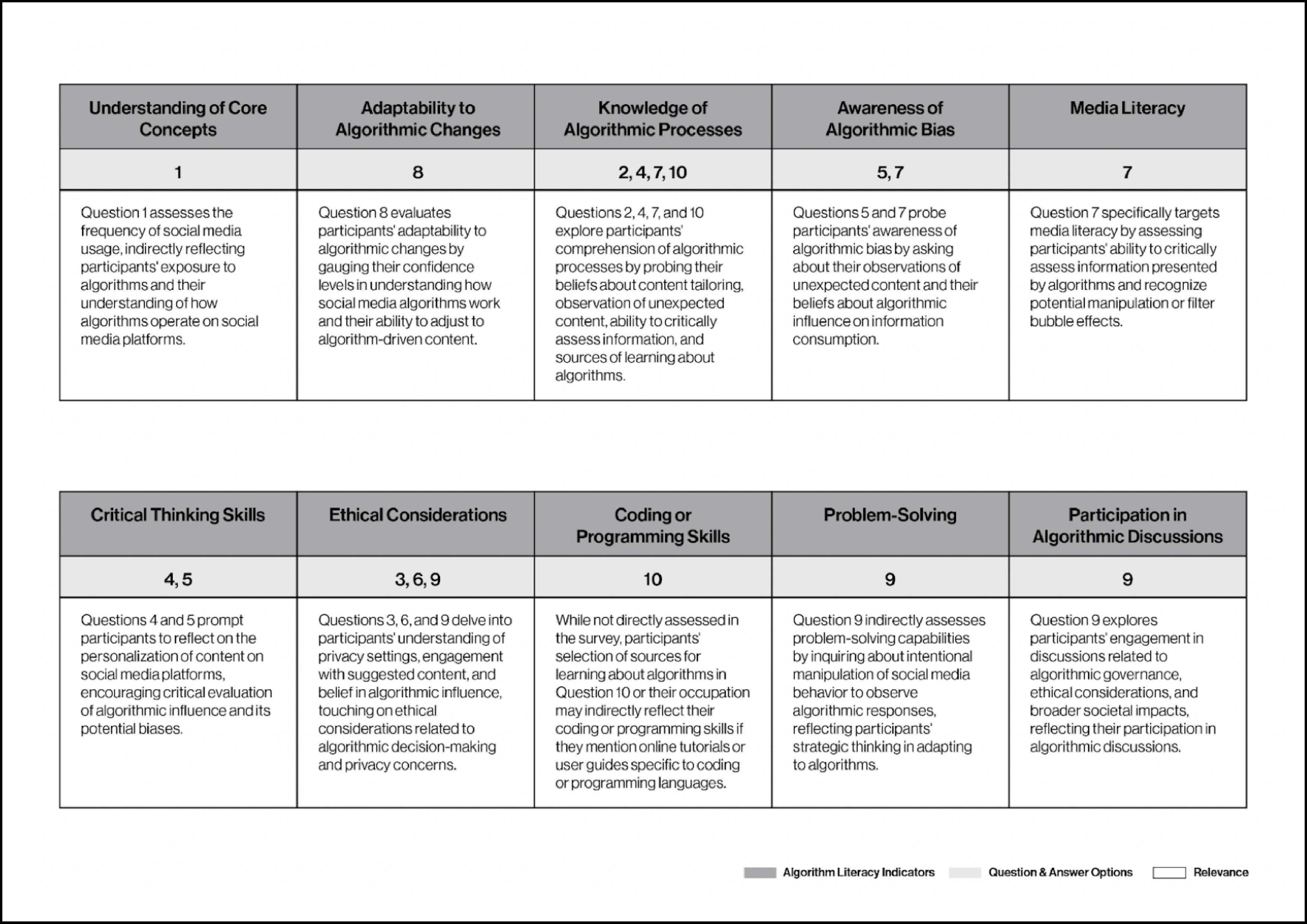
Preliminary Survey Relevance to Indicators
Transcribing Experiment Discussions
Prior to calibrating the literacy levels, I needed to transcribe the experiment discussions for reference
and to refresh my memory on the key points discussed.
Transcribing Experiment 1 was relatively straightforward compared to Experiment 2. Experiment 2 presented
challenges due to overlapping conversations, making it difficult to maintain the exact sequence. To
address this, I grouped together some responses from the same subjects and omitted instances of Singlish.
I took great care to ensure that these modifications didn't alter the meaning of the responses, and I used
brackets to indicate when subjects or I were responding to another subject.
Throughout the experiment, I maintained consistency in the sequence of my question prompts across both
Experiment A and B, facilitating easy reference. The transcript was divided into front and back ends to
signify the experiment phase in which the discussions occurred. Additionally, I highlighted the question
prompts in the transcript to aid in identification.
Transcript
Calibrating Algorithm Literacy Levels
During the experiment, I observed certain irregularities in the algorithm literacy levels among my
subjects. Subject C, despite scoring lowest in the ALEC due to infrequent social media usage, exhibited a
high understanding of algorithms but lacked media literacy. Recognizing this anomaly, I refrained from
dismissing it as an isolated case, drawing from personal experiences of friends who are not on social
media yet comprehend its functioning well. This realization prompted a significant shift in my
post-evaluation approach.
In the calibration of the ALEC, I noted an overall increase in subjects' scores. Subsequent investigation
revealed that this disparity stemmed from using social media literacy as a divergence in the preliminary
survey, a suspicion I had while analyzing Subject C's data during the experiment. Given the tight
timeline, I reluctantly accepted the existing survey results and planned to address this limitation in my
study.
Calibrating the scores proved mentally taxing as I grappled with the recurring question, "Who am I to
determine their algorithm literacy levels?" Contemplating involving friends for a more impartial
evaluation, I ultimately dismissed the idea due to time constraints.
To enhance analysis, I included the change from initial scores in each indicator of the calibration ALEC.
However, deciphering trends amidst the array of numbers proved challenging. Considering this, I
contemplated creating visual aids like bar charts or graphs to facilitate better understanding.
During calibration, I realized a reflection of an oversight present in my experiment: the absence of
elements related to 'Coding or Programming Skills,' resulting in no discernible change in the ALEC scores.
This highlighted the need for a more comprehensive evaluation framework.
Preliminary Scores
Calibrated Scores
Post-experiment Literacy Levels
In the post-experiment ALEC, scores could only remain the same or increase; there was no possibility of a
decrease. Thus, I intentionally reserved the maximum score (5) for subjects who truly merited it.
Moreover, subjects' responses in the post-experiment survey needed to justify their self-assessed
algorithm literacy gains.
In general, subjects' scores increased by 1 point in indicators where they noted improvements. Subject F
presented a special case, demonstrating extensive knowledge gain across various indicators, warranting 2
points instead of 1, as supported by their response.
Despite the absence of a component targeting 'Coding and Programming Skills' in my experiment, some
subjects surprised me with indications of takeaways in this indicator. While I had intended the question
'challenges in creating Inclusivision' to prompt discussions about algorithmic considerations, the
responses veered off-topic, at least in my perception. However, the reveal workshop helped these subjects
realize and reflect on their discussions, leading to gains in knowledge in the 'Coding and Programming
Skills' indicator.
I'm currently thinking about the format of my ALEC and its presentation in my dissertation. In each
evaluation phase discussed, I plan to include the ALEC scores alongside the change in scores. However, for
a comprehensive overview of each individual, I believe it would be more practical to include it in the
Appendix, allowing readers to refer to it alongside the main text.
Post-experiment Scores
Concluding Discussion
To conclude my discussion, I initially planned to analyze any patterns or trends in the ALEC scores, along
with subject responses to assess the effectiveness of my experiment. However, merely staring at the
numbers didn't reveal any significant insights. This process was time-consuming as I had to meticulously
cross-reference the data with the transcript and participant responses to confirm potential patterns or
trends, which often turned out to be inconclusive.
Due to time constraints, I turned to AI for assistance. Collating my transcript, ALEC scores from each
phase, and participant responses, I sought help from ChatGPT to identify patterns and trends.
Unfortunately, the major trend identified by ChatGPT was one I had already observed—the overall increase
in scores across all individuals. Most of the other results provided by ChatGPT were either exaggerated or
misdirected upon cross-referencing with my data.
Given the lack of discernible patterns, I decided to justify my conclusions based on the overall score
increase. Thus, I reframed the section title to 'Comparing calibrated initial scores to post-experiment
scores,' allowing me to summarize the ALEC overview from phase to phase and explain the possible reasons
for the change. Additionally, I identified two significant points regarding Subject C and F, adding an
additional layer of consideration and evident effort in addressing anomalies.
In the final paragraph, I tied the findings back to my research objectives. With this, it felt like the
conclusion of my study. The experiment and measurement sections constitute the main bulk of my challenge,
while the discussion section primarily helped identify limitations and round up the conclusion. This
additional time will allow me to refine these sections further. Furthermore, the reference illustrations I
created can serve as figures and appendices in my dissertation as well.

Snippet of Discussion Conclusion
Addressing Research Limitations
Throughout the planning, conducting, and reflection phases of my project, I diligently documented the
specific limitations inherent to my research, steering clear of framing them as common Final Year Project
(FYP) constraints. Instead, my focus remained on limitations exclusive to my project, acknowledging their
inevitability given the nature of my research. Despite this, I made concerted efforts to mitigate their
impact by adopting appropriate strategies and noting down the causes for future reference.
Limitation 1:
The sample size of the experiments and the diversity of participants represent the primary limitation.
Conducting more experiments with a larger and more diverse sample size could have provided deeper insights
into algorithm literacy gain, considering factors such as age groups, educational backgrounds, and
cultural diversity.
Action: I addressed this limitation by selecting participants with varying algorithm literacy levels and
age groups, albeit within the constraints of the project's scope.
Limitation 2:
Another significant limitation involves the subjective interpretations of participants' algorithm literacy
and self-assessments, which inherently introduce bias.
Action: To mitigate this, I cross-referenced participants' self-assessments in the post-experiment survey
with their conversations during the experiment. Additionally, participants were required to provide
detailed justifications for their self-evaluations, enhancing the reliability of the data.
Limitation 3:
The duration of participant engagement with the software prototype and discussions was confined to the
experimental sessions, potentially impacting the depth of understanding and sustainability of algorithm
literacy gains over time.
Action: Recognizing the time constraints inherent in student FYPs, I acknowledged this as a general
limitation affecting all projects adopting a similar approach. While potential solutions exist,
implementing them was unfeasible within the project's timeframe.

Snippet of Dissertation Limitations