░░░░░░░ WEEK 4 ░░░░░░░
Major Changes
The conversation with Andreas was stressful as it uncovered many gaps between my research objective and
method. Thankfully, the identification of Discursive Design as my main approach helped me to redirect and
narrow down my research’s focus to solely fostering algorithm literacy.
I initially had 2 research objectives, which Andreas deemed the latter too ambitious. More so, it was
impossible to arrive at a reasonable conclusion with the limited time that I have. With the removal of the
second objective, I had the word count to introduce the prototype and thought experiment early. I was also
able to be more specific about ‘fostering algorithm literacy’, directing the focus to navigating the
dilemmas previously touched on in my literature review.
Andreas also highlighted the importance of mentioning how my prototype prioritises sparking discourse
rather than functionality - which was missing in my dissertation. He also mentioned the need to be
extensively descriptive on my processes, justifying my decisions and communicate my research clearer. I
hope by doing this, it clears up any possible misunderstanding surrounding my research method.
Prior to writing my dissertation, I had already browse through the Discursive Design book by Bruce M.
Tharp and Stephanie M. Tharp, so I had sufficient foundational understanding of the approach to make
changes. This also helped me to eliminate my previous concerns of the Research through Design approach as
I wasn’t inquiring knowledge through the design process, but through the results of my thought experiment.
The Process Reflection Tool was also a little bit restrictive to the documentation structure my
experiments required, so removing that opened up a more flexible documentation possibilities.
In the methods section of my dissertation, I also added 2 more paragraphs, detailing the step by step
process of how algorithm literacy will be evaluated, as well as explaining the construction of the
Algorithm Literacy Evaluation Chart.

Previously ambitious research objective

Updated research objective targets
Finalising Measurement Method
I had a lot of trouble organising my thoughts on how I can measure the effectiveness of my method which
points towards the conclusion in my dissertation. The metric for success is really straightforward, find
the initial algorithm literacy level of participants before the experiment, measure again after the
experiment, then compare them to find the percentage of algorithm literacy gain. As simple as it sounds,
there are a few complications with this method of assessment.
Each of these problems encase more problems within themselves that require solutions, in the following
paragraphs, I’ll elaborate on them, as well as how I overcame them.
Problem 1
Determining algorithm literacy levels before the experiment without revealing to participants that the
alpha test is an experiment on algorithm literacy poses a challenge.
One approach is to design a survey focused on discovering participants' knowledge and familiarity with
social media. Each question would correspond to an indicator of algorithm literacy in the Algorithm
Literacy Evaluation Chart (ALEC). By analyzing their responses, we can gauge their literacy levels based
on the ALEC scores.
However, this method relies on indirect questions, leading to assumptions about participants' initial
algorithm literacy levels. To address concerns about data validity, I consider leveraging the reliability
of the ALEC indicators, grounded in extensive research. This justification supports the assumption that
the survey results should offer valid insights into participants' algorithm literacy levels.
Acknowledging the subjectivity of this approach, I propose keeping the initial literacy scores unfinalised
to leave room for calibrating assumed literacy levels based on additional participant insights during the
experiment. For instance, if a participant scores low in Coding & Programming skills but later reveals
coding experience, their score could be recalibrated based on the depth of their experience. This
iterative process enhances the accuracy of algorithm literacy assessments.
Problem 2
The second challenge revolves around determining participants' algorithm literacy levels after the
experiment concludes. Upon revealing the true purpose of the alpha test, participants will partake in
another survey where they self-assess their perceived gains in algorithm literacy across each algorithm
literacy indicator.
This self-assessment approach contrasts with the initial qualitative evaluation method, raising concerns
about reliability. To address this, I've introduced an additional question for each indicator in the
survey, prompting participants to elaborate on their learning experiences. Subsequently, I will evaluate
each response and assign scores in the ALEC based on the depth of their insights. This dual evaluation
strategy aims to maintain consistency in measuring the experiment's effectiveness while enhancing the
reliability of the assessment process.

Algorithm Literacy Measurement Flow
Question Prompts
One of my biggest concerns right now is if the participants don’t talk to each other. As participants’
responses will be evaluated to determine the success of the experiment, a list of question prompts would
need to be prepared to kickstart discussions.
To ensure that every single indicator of algorithm literacy is addressed in my experiment, I came up with
1 question for each indicator. These questions are all phrased within the context of the narrative.
Furthermore, I listed some possible answers that I’m looking for so on the day itself, I can refer to them
to come up with questions on the spot to hopefully prompt them. I also separated the questions into
front-end and back-end, categorizing them according to the order when they should be ordered.
I foresee some discussions will consist of overlaps between indicators and welcome that. I’m prepared to
redirect questions and ensuring every participant receives an opportunity to participate and contribute to
the discussions.
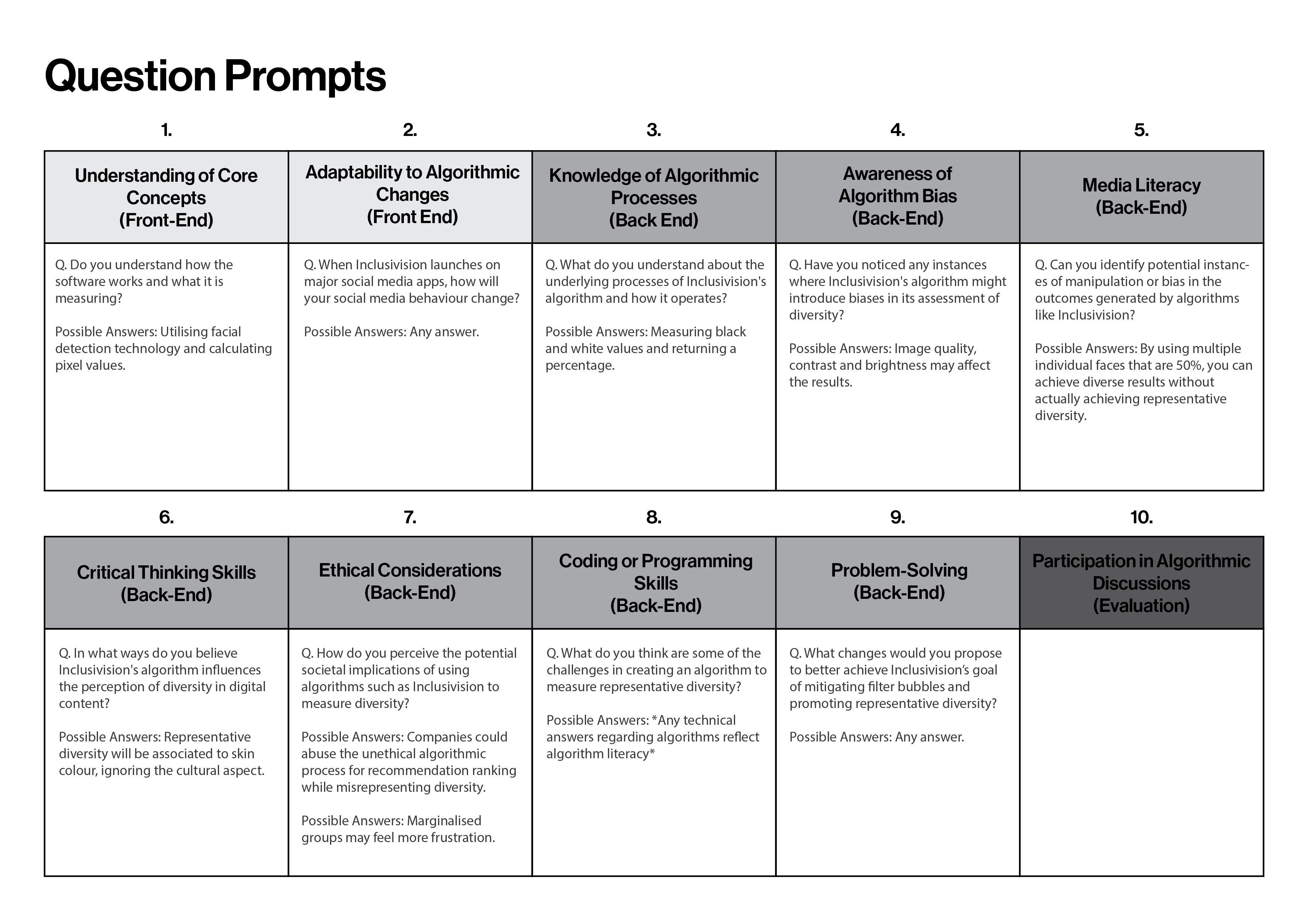
Experiment question prompts
Experiment Preparation
Before the test, I conducted a preliminary survey with 15 participants and selected 6 based on their
initial algorithm literacy levels. Each experimental session includes 1 participant with limited algorithm
literacy, 1 proficient, and 1 advanced, showcasing diverse responses across different literacy levels.
Additionally, I intentionally included participants from underrepresented groups in Singapore to gather
insights into their perspectives on Inclusivision's narrative.
For each participant, I prepared 1 laptop and 1 monitor. However, due to space constraints, accommodating
3 monitors on the table setup wasn't feasible, so I opted for iPads instead.
I also arranged for 2 cameras: one for documentation purposes and another on a tripod to capture
participant reactions. A friend will assist me in documenting behind-the-scenes footage during the
experiment. Regarding audio recording, I installed and tested a microphone positioned just above the
participants' seating area. However, capturing audio might pose challenges due to the fixed placement of
the microphone rig. Participants may need to speak louder for the microphone to capture clear audio, as
adjusting the gain could introduce background noise.

Technical setup
Introductory Slides
Before each experiment session, I will spend some time introducing Inclusivision to the participants. The
purpose is to convince them of Inclusivision’s narrative, suspending their disbeliefs before their
interaction with the software prototype.
The first crucial point to deliver is the mission of promoting inclusive representation and mitigating
filter bubbles. This reminds the participants of the software’s goal going into testing the software. The
next point is to communicate how the software will be applied in real life. By telling the participants
that Inclusivision plans on partnering with major social media platforms, it prompts them to consider the
implications in the digital landscape.
The final point briefs participants on what their roles are as alpha testers. Their contributions
basically encompass providing honest feedback and to participate in active discussions.
I added 2 more slides to be referred to after the commencement of the alpha test. These 2 slides cover the
main ‘unethical’ elements in the front-end and back-end of the software, absurdly justifying the unethical
decisions, in hopes to trigger a response and spark discussion.
Introductory slides
Experiment Day
Experiment 1
Right at the beginning of the experiment, there was a technical issue where two of the iPads failed to
mirror the MacBook screen, which required approximately 15 minutes to troubleshoot and resolve. This cut
short the amount of time I had with the first experiment session, resulting in me unnecessarily rushing
through the introduction, leaving out a few key points which I had to reiterate during the experiment.
During the experimentation phase, one of the subjects successfully tested the live screen recording input,
reporting positive results. However, when another subject attempted to upload their own photos for testing
purposes, they encountered difficulties, particularly with facial detection misidentifying faces more
frequently than usual. This issue was speculated to be related to image size, which I had noted before but
had forgotten to resolve.
Throughout the discussions, there was a noticeable formality among participants, likely stemming from a
reluctance to inadvertently offend me or the perceived "company" I represent. Consequently, participants
seemed cautious in their choice of words, potentially hindering their ability to provide candid feedback
and fully express their concerns. During the subsequent reveal workshop, participants demonstrated a
notable shift towards openness, confirming my initial assumptions. They clarified and expanded upon points
raised before during the experiment, showing a newfound comfort in expressing opinions without fear of
causing offense or misunderstanding the software's intentions.
In the guided post-experiment survey, I’m very thankful that the participants displayed strong
supportiveness, actively seeking clarification, and assisting each other in recalling specific events.
Notably, they took their time with each question, providing thorough answers and elaborating where
necessary.
Experiment 2
In reflecting on the session, it became apparent that the atmosphere was initially more casual, especially
given that two participants already knew each other beforehand. Initially concerned that the discussions
might not delve into serious topics, I found that when questions concerning ethicality and societal
implications arose, the tone of the conversation shifted noticeably, becoming more serious and concerned.
During this session, it also became apparent that certain gaps existed within the experiment's design. One
notable gap pertained to the exploration of representative diversity, an aspect I had underemphasized.
Interestingly, participants identified this oversight as akin to algorithmic decision-making bias, which
prompted them to engage in discussions about its implications.
The conversations in this experiment leaned more towards representative diversity than the algorithms.
They were constantly going away from algorithms, however, the question prompts were able to pull them
back.
Throughout the second experiment, the discussions tended to veer towards representative diversity rather
than focusing solely on algorithms. Despite this tendency to stray, the guided question prompts
effectively steered the conversations back to the intended topics.
Following the experiment, during the guided post-experiment survey, it became apparent that participants
did not approach the survey with the same level of seriousness upon learning it was part of the
experiment. Consequently, I had to request them to retake the survey in order to gather more meaningful
and authentic responses. It was really awkward for me to impose but I really needed genuine data to work
with or my dissertation discussion would suffer.
Reflection
One of my biggest worries before the experiment was that the participants would catch on, potentially
discerning the true intention behind the test. To prevent that, I had keep my composure and acted like
they were my clients even though they were friends of my friends. At the end of the experiments, I’m
thankful that it all went well and I got the results that I wanted. I had planned meticulously and even
prepared myself by playing through the flow of the experiment in my head over and over again. I find that
this helps me to catch possible issues and questions that might come up and prepare me to confidently
address them.
One particular oversight that I didn’t address was the algorithm literacy indicator of coding or
programming skills. The question prompt that I had asked was too indirect. The ideal response to the
question of ‘What do you think are some of the possible challenges in designing an algorithm like
Inclusivision?” would be more technical, but all my subjects responded to it from a more general
standpoint.
At the start of the experiment, I was also a little concerned about the structure of the question prompts.
When subjects elaborated on their answers, their elaborations were somewhat related to the questions I
haven’t gotten to ask yet. I had considered to switch up the questions to make it easier to flow from one
discussion topic to another, but to maintain consistency across both experiments, I just followed the same
order. I was worried that it might’ve created an impression that I don’t care about their replies as I
kept saying ‘let’s move on for now’, especially in the 2nd experiment session. When I clarified and
apologised for that after the experiments, my participants told me that they didn’t feel that way and I
was overthinking, which made me feel more relieved.
Even though I got what I wanted to achieve, another issue loomed over me. I was getting anxious and
worried about how I’d process the findings, evaluate the results etc. On paper it sounded easy, but it was
going to take up a lot of my mental capacity to process them. I needed a clear mind to ensure that I stay
consistent in the evaluation, ensuring fairness. I also noted down a few oddities that I needed to find a
way to address in my evaluation. These oddities I’m referring to are subjects that displayed high
algorithm understanding, despite being assigned a low algorithm literacy level following the preliminary
survey. I would need to calibrate their scores and justify them accordingly.
For now, I’m planning to take the rest of the week off to repay my sleep debt. I know I deserve this,
especially since I’ve overcame one of the greatest hurdles in my project. All my worries about the thought
experiment going wrong has now gone away. Thinking back, it was really a bold attempt to conduct a thought
experiment to justify my research without having a clue about how it would go. High risk high reward I
guess!

Experiment Group 1

Experiment Group 2

Helping Participants Navigate the Software

Explaining Back-End Processes

Discussions Surrounding Algorithm Ethics